Multiple granularity is a database locking technique that allows various data items of different sizes and set locks on them and also defines the hierarchy of data granularity where small granularities are nested within the larger granularity.
There are three types of lock granularity
- Course granularity: It is used to lock tables, files, databases, and records. It reduces the transaction number and decreases the throughput to increase the response time of the transaction. But this also causes the concurrency to get reduced.
- Fine granularity: It locks the records and fields to provide high concurrency and throughput. But it leads to very high overhead and low response time.
- Intermediate granularity: It locks equal and fixed-size pages that contain a few rows and columns of one or more tables of the database.
Multiple granularity breaks the database into a number of blocks that can be locked to increase the concurrency and decrease the lock overhead. It also makes it easy to decide which segment or part of data to lock or which one to unlock. The hierarchy of data of various sizes is represented using a tree where the node represents the database the next level of the node represents the files and then the next level shows the records of that database.
For example
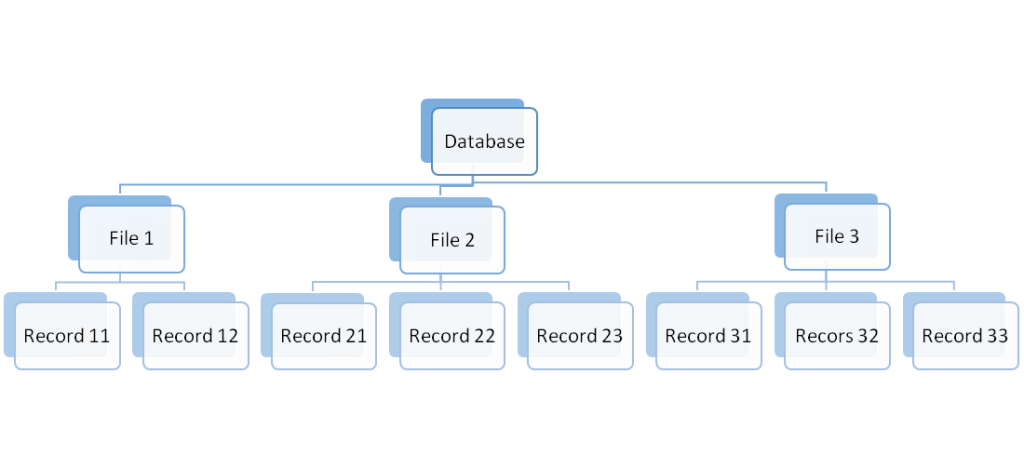
The additional locks are used to achieve multiple granularity and these locks are named intention locks which guide the path from the root node to the desired node for a transaction.
There are 3 intention locks types
- Intention shared (IS) lock: this lock indicates that one or more shared locks can request on some nodes.
- Intention exclusive (IX) locks: this lock indicates that one or more exclusive locks can request on some nodes.
- Shared intention exclusive (SIX): this lock indicates that the shared lock locked the current node but still one or more exclusive locks can request on some nodes.